
Tuesday morning, millions of people woke up to find their favorite apps and websites completely dead. No ChatGPT. No Spotify. No X. Even Downdetector, the site everyone uses to check if services are down, went offline.
The culprit? A single company most people have never heard of: Cloudflare. And CEO Matthew Prince admits this was the company’s worst outage in six years.
But here’s what should worry you more. This keeps happening. Different companies. Same catastrophic results. The internet’s foundation is more fragile than anyone wants to admit.
What Actually Broke
Cloudflare powers roughly 20% of all websites globally. When it goes down, a massive chunk of the internet disappears with it.
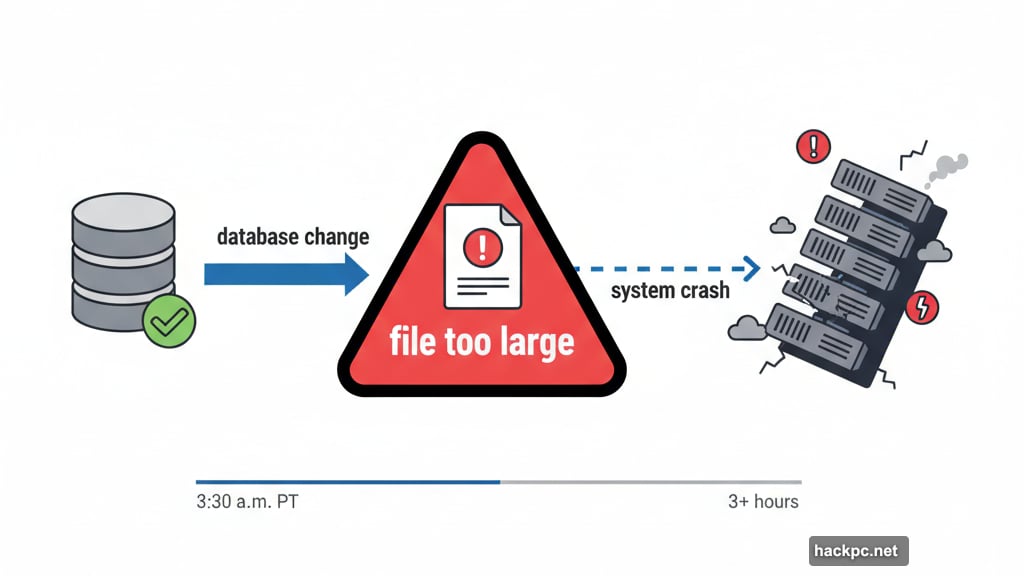
The outage started around 3:30 a.m. PT on Tuesday. Within minutes, services across the internet began failing. Users saw nothing but error messages. Companies lost revenue by the second.
For over three hours, chaos reigned. Then Cloudflare engineers found the problem. A database change created a file too large for their software to process. So the system simply crashed.
Prince explained the technical details in a blog post later. “Given Cloudflare’s importance in the Internet ecosystem any outage of any of our systems is unacceptable,” he wrote. The apology sounds sincere. But the damage was already done.
The Scale of Destruction
Downdetector received over 2.1 million problem reports during the outage. That’s not counting people who couldn’t access Downdetector itself to report issues.
The United States took the biggest hit with 435,000 reports. But the disruption spread globally. The UK, Japan, and Germany saw massive problems too.
Here’s a snapshot of what went dark:
- ChatGPT and OpenAI services: 81,000 reports
- Spotify: 93,000 reports
- X (formerly Twitter): 320,000 reports
- League of Legends: 130,000 reports
- Grindr: 25,000 reports
Plus smaller services like Letterboxd, Canva, and Etsy. Shopify merchants couldn’t process orders. Gamers couldn’t log in. People couldn’t stream music or check social media.
Forrester analyst Brent Ellis estimates the total economic damage at $250-300 million. That includes direct losses from downtime plus ripple effects across businesses that depend on these platforms.
Why This Keeps Happening
Remember the Amazon Web Services outage last month? That killed Reddit, Snapchat, Roblox, and Fortnite. Before that, CrowdStrike’s failure disrupted airlines and hospitals worldwide. Fastly went down in 2021, taking CNN, Reddit, and Amazon with it.
Different companies. Same pattern. The internet runs on a handful of massive infrastructure providers. When one fails, millions of services collapse simultaneously.
Sarah Kreps from Cornell’s Tech Policy Institute puts it bluntly: “This multibillion, even trillion-dollar investment in AI is only as reliable as its least scrutinized third-party infrastructure.”
She’s talking about ChatGPT going dark Tuesday morning. But the point applies everywhere. Companies pour billions into AI development. They build elaborate cloud services. They promise seamless global connectivity.
Then a database file gets too big. And everything stops working.
The Real Risk Nobody Wants to Discuss
Cloudflare insists Tuesday’s outage wasn’t a cyberattack. They initially suspected a massive DDoS attack. Turns out it was just a software bug. An internal failure.
Here’s the scary part. If an internal error can cause this much damage, imagine what a coordinated attack could do. These infrastructure companies are massive single points of failure.
Plus, companies keep consolidating around these same providers. Why? Cost and convenience. AWS, Cloudflare, and similar services offer incredible scale and reliability. Most of the time.
But “most of the time” isn’t good enough when you’re powering 20% of the internet. One mistake takes down thousands of services simultaneously. Millions of users lose access. Businesses bleed money.
The current approach creates what Forrester calls “concentration risk.” Too much infrastructure depends on too few companies. There’s no real backup plan when these systems fail.
What Could Actually Change
Engineers will tell you perfect uptime is impossible. Systems fail. Software has bugs. Hardware breaks. That’s reality.
But here’s what doesn’t have to be reality: having so much of the internet dependent on so few providers. Decentralization used to be the internet’s strength. Now it’s increasingly centralized around a handful of companies.
Some solutions exist. Companies can use multiple cloud providers instead of relying on one. They can build redundancy into their systems. They can maintain their own infrastructure for critical services.
Yet most don’t. Because it’s expensive. Because it’s complex. Because AWS and Cloudflare work great 99.9% of the time.
That last 0.1% just cost the internet $300 million.
The Pattern We Can’t Ignore
Here’s what frustrates me most. These outages follow a predictable script. Major infrastructure provider goes down. Thousands of services fail. Company apologizes. Engineers fix the problem. Everything returns to normal.
Then three months later, it happens again with a different company. Same disruption. Same economic damage. Same collective shrug and moving on.
Meanwhile, our dependence on these centralized services only grows. More AI tools. More cloud migration. More critical systems running on infrastructure that can disappear in minutes.
Cloudflare brought most services back online within three hours Tuesday. That’s actually impressive crisis response. But we shouldn’t need impressive crisis response this often.
The internet deserves better infrastructure. We deserve better redundancy. Companies building on these platforms deserve honest conversations about the risks they’re taking by centralizing everything.
Until that changes, expect more mornings like Tuesday. Different company next time. Same frustrating result.



Comments (0)