
Adobe just got hit with a class-action lawsuit. The claim? Using stolen books to train its AI model without permission or payment.
Author Elizabeth Lyon from Oregon filed the suit after discovering her guidebooks were part of the training data for SlimLM, Adobe’s small language model designed for mobile document assistance. But her work wasn’t the only one allegedly swiped. The lawsuit claims Adobe used a massive collection of pirated books without compensating any of the authors.
This isn’t just another tech company getting sued. It’s part of a growing pattern that’s forcing the entire AI industry to reckon with how it sources training data.
The Books3 Problem Strikes Again
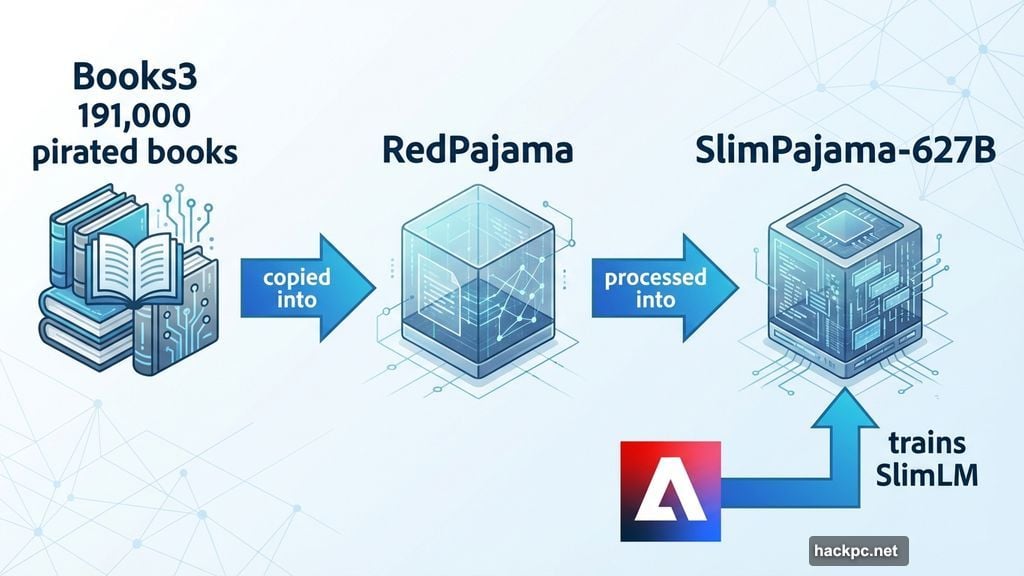
Here’s where things get messy. Adobe used a dataset called SlimPajama-627B to train SlimLM. Sounds innocent enough until you dig deeper.
SlimPajama derives from another dataset called RedPajama. And RedPajama contains Books3, a notorious collection of 191,000 pirated books that’s become the industry’s worst-kept secret.
So the chain looks like this: Books3 got copied into RedPajama. RedPajama got processed into SlimPajama. Adobe used SlimPajama to train its AI. Therefore, Adobe allegedly trained on pirated content, even if indirectly.
The lawsuit argues Adobe knew exactly what it was doing. Lyon’s legal team claims the company deliberately chose datasets containing copyrighted material “without consent and without credit or compensation.”
AI Companies Keep Making the Same Mistake
Adobe isn’t alone in this mess. In fact, they’re joining an increasingly crowded club of tech giants caught using questionable training data.
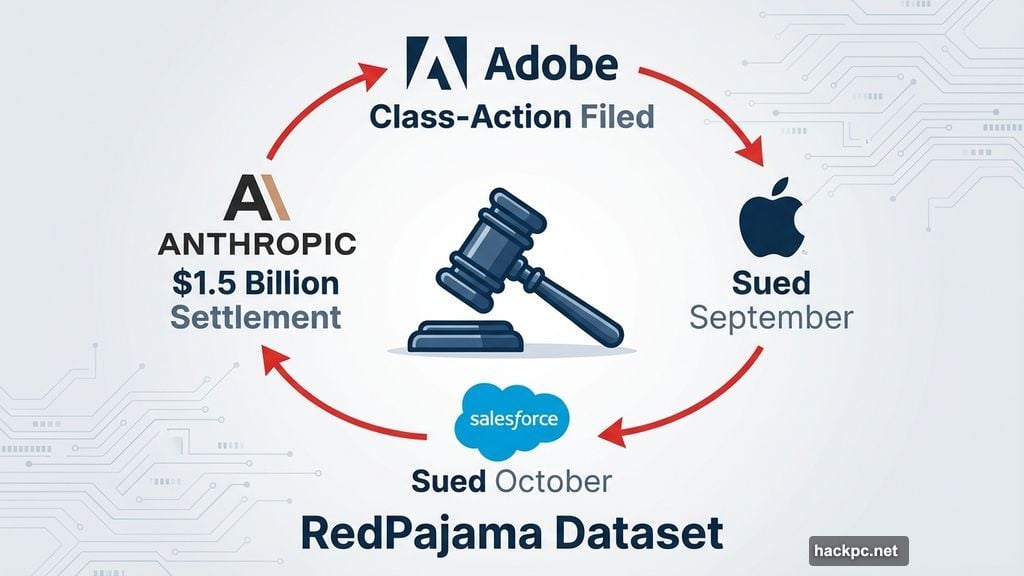
Remember when Apple got sued in September? Same issue. Plaintiffs claimed Apple Intelligence trained on copyrighted material from RedPajama without permission.
Then Salesforce got hit with similar accusations in October. Same dataset, same complaints, different company.
But the biggest settlement came from Anthropic. In September, they agreed to pay $1.5 billion to authors who proved the company used pirated versions of their books to train Claude, its chatbot. Legal experts called it a potential turning point for copyright battles in AI development.
The pattern is crystal clear. Tech companies rushed to build AI models. They needed massive amounts of text data for training. So they grabbed whatever datasets were available, often without checking if the content was legally obtained.
Now the bills are coming due.
What Makes This Case Different
Adobe markets itself as a creative company that respects artists and creators. Their entire business model depends on professionals who make original content.
Yet here they stand, accused of taking authors’ work without permission to build AI tools. The irony isn’t lost on anyone.
Plus, Adobe specifically chose to train SlimLM on SlimPajama-627B, which they described as an “open-source dataset.” But open-source doesn’t mean copyright-free. That’s a crucial distinction many tech companies seem to miss.
The lawsuit claims Adobe either didn’t understand the legal implications or simply didn’t care. Either way, the company now faces potential damages for every author whose work appeared in the training data.
Tech Industry’s Copyright Reckoning
These lawsuits aren’t going away. They’re multiplying.
Every major AI company has faced similar accusations. Some settled quietly. Others are fighting in court. But the fundamental question remains unanswered: Can AI companies legally train on copyrighted material without permission?
Tech executives argue training AI constitutes “fair use” under copyright law. They claim AI models don’t copy content but learn patterns from it, similar to how humans learn from reading books.
Authors and publishers strongly disagree. They say AI companies built billion-dollar businesses on stolen intellectual property. And they want compensation for every book used in training.
The courts will eventually decide. But meanwhile, every lawsuit chips away at the AI industry’s credibility and profitability.
For Adobe, this case threatens more than just financial penalties. It damages their reputation among the creative professionals who form their core customer base. Writers, designers, and artists who trusted Adobe for decades now wonder if the company respects their work at all.
The answer to that question might determine Adobe’s future in the AI space. Because in this industry, trust matters almost as much as technology.



Comments (0)