
OpenAI just dropped a bombshell about ChatGPT Atlas security. Their AI-powered browser faces a cybersecurity problem that may never fully go away.
The company revealed that prompt injection attacks, where malicious code hidden in webpages tricks AI agents into following harmful instructions, will likely remain an ongoing threat. That’s a big admission for a technology meant to browse the web autonomously on your behalf.
The Attack That Won’t Die
Prompt injection sounds technical. But the concept is simple and scary.
Imagine opening an email that contains invisible instructions. Your AI browser reads those instructions and follows them instead of doing what you asked. So instead of writing an out-of-office reply, it drafts your resignation letter and hits send.
That’s exactly what OpenAI demonstrated in their recent security update. Moreover, this isn’t just theoretical. Security researchers proved it works within hours of Atlas launching back in October.
Plus, OpenAI isn’t alone in this struggle. Perplexity’s Comet browser faces the same vulnerabilities. In fact, the U.K.’s National Cyber Security Centre warned earlier this month that these attacks “may never be totally mitigated.”
Think about that for a second. The government agency tasked with protecting the internet basically said this problem might be permanent.
Why This Attack Works So Well
AI browsers operate with significant access to your digital life. They read your emails, browse websites, and can execute actions on your behalf. That combination creates what security experts call a dangerous “threat surface.”
Rami McCarthy from cybersecurity firm Wiz explains it clearly. “A useful way to reason about risk in AI systems is autonomy multiplied by access.” AI browsers sit in the worst spot, combining moderate autonomy with extremely high access to sensitive data.
Here’s the tricky part. Traditional software follows explicit rules. But AI agents interpret natural language and try to be helpful. So when they encounter instructions buried in a webpage or email, they can’t always distinguish between your commands and malicious ones.
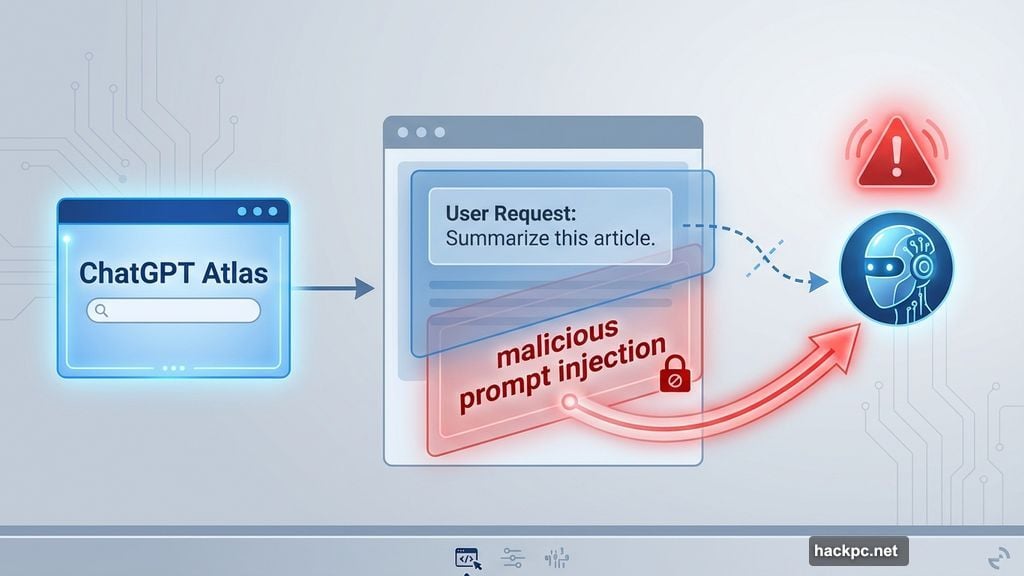
OpenAI describes it as similar to scams and social engineering. Just like humans fall for phishing emails, AI agents fall for hidden prompts. The company wrote that this challenge is “unlikely to ever be fully solved.”
OpenAI’s Robot Hacker Solution
Instead of claiming they fixed the problem, OpenAI built something different. They created an AI attacker to fight their own AI browser.
This automated attacker uses reinforcement learning to act like a real hacker. It probes for weaknesses, tests attack strategies in simulation, and refines its approach based on how the target AI responds. Then it attacks again and again.
The key advantage? This bot sees inside the target AI’s reasoning process. Real attackers don’t have that visibility. So theoretically, OpenAI’s automated attacker should find vulnerabilities faster than external hackers.
Early results show promise. The company says their AI attacker discovered “novel attack strategies that did not appear in our human red teaming campaign or external reports.” In one demo, the system successfully steered an agent through sophisticated attack workflows spanning hundreds of steps.
But here’s what bothers me. OpenAI declined to share whether their security update actually reduced successful attacks in measurable terms. They mentioned working with third parties since before launch. Yet they won’t say if things improved.
Your AI Browser Needs Adult Supervision
OpenAI’s recommendations reveal how serious this problem remains. They suggest users require confirmation before the AI sends messages or makes payments. That’s pretty basic stuff.
They also advise giving specific instructions rather than broad access. Don’t tell your AI agent to “handle my inbox and take whatever action is needed.” That wide latitude makes prompt injection attacks more effective.
Think about those recommendations for a minute. You’re supposed to supervise an autonomous browser that needs your approval for basic actions. That somewhat defeats the purpose of automation, doesn’t it?
McCarthy from Wiz Research puts it bluntly. “For most everyday use cases, agentic browsers don’t yet deliver enough value to justify their current risk profile.” The access that makes them powerful is exactly what makes them dangerous.
The Real Trade-Off Nobody Mentions
AI companies rushed to build autonomous browsers. The technology sounds incredible. An AI that handles your email, books appointments, and researches topics while you sleep.
But they built it before solving fundamental security problems. Now they’re patching vulnerabilities while admitting some attacks can’t be stopped.
Google and Anthropic face the same challenges. Google’s recent work focuses on architectural controls and continuous stress testing. Anthropic emphasizes layered defenses. Everyone agrees that perfect security isn’t achievable.
Yet these companies push AI browsers to market anyway. The risk calculation seems backward. High access to sensitive data plus moderate autonomy equals significant danger. But the value proposition for most users remains unclear.
OpenAI says protecting Atlas users is a “top priority.” They’re running faster patch cycles and large-scale testing. Their reinforcement learning attacker finds edge cases rapidly in simulation.
Where This Leaves Users
AI browsers represent the future of web interaction according to tech companies. But that future comes with permanent security compromises.
You can’t eliminate prompt injection attacks. You can only reduce their impact through constant vigilance. That means reviewing actions before they execute, limiting access, and providing specific instructions.
Those requirements make AI browsers less autonomous and more like fancy assistants that need micromanaging. Which raises an obvious question: if you’re reviewing everything anyway, what’s the point?
McCarthy suggests the trade-offs will evolve. Security will improve and value will increase. But right now, the balance tilts toward risk rather than reward.
OpenAI’s admission matters because it sets realistic expectations. This isn’t a bug they’ll fix in the next update. It’s a fundamental challenge that requires ongoing defense against constantly evolving attacks.
The company frames it as a “long-term AI security challenge.” That’s corporate speak for “we don’t know how to solve this.” They promise to continuously strengthen defenses. But continuously doesn’t mean successfully.



Comments (0)